Jacky
教土豆学计算机
Basic Architecture
基于微服务架构的系统本质上是一个分布式系统, 整个系统由众多微服务 cell 组成, 协作完成所需功能. 从模块化的角度来说, 单个微服务 cell 就是一个模块, 具有明确, 单一职责, 且充分自治.
 来源 “Microservices a definition of this new architectural term”
来源 “Microservices a definition of this new architectural term”
这里从分布式系统理论出发看微服务系统的架构.
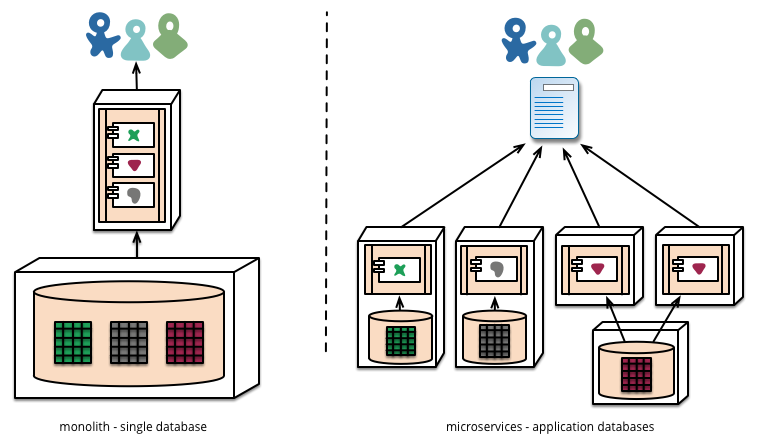
模块化 - 服务拆分
如何将系统拆分为多个微服务 cell? 常见思路是首先进行业务分析(系统功能性需求, 建模?); 先进行业务拆分, 后服务拆分.
Namespace 命名系统
名称在所有计算机系统中都起着重要的作用; 它们用来唯一标识资源, 指向位置等. 当今世界上最大的分布式命名系统就是因特网的域名系统 DNS. 同样,在微服务世界里, 服务也需要一个标识, 以便其他服务可以访问. 因此需要一个 服务注册与服务发现 机制;可以选择的技术方案有 Zookeeper,Etcd(Raft), Consul
通信
分布式系统中的进程间通信是所有分布式系统的核心,通常有二种选择:直接通过网络进行数据(信息)交换, 或读写某些共享存储
RPC
直接通过网络进行数据交换的一种广泛使用的技术是 RPC 或 RMI; 开源的跨语言 RPC 框架有 Thrift,Google Protocol Buffers
MQ
RPC 存在的一个问题是, 它要求客户端与服务端必须同时工作, 此外 RPC 的同步特性也造成客户端在发出请求得到响应之前会被阻塞. 因此, 有时我们需要采取其他方法, 通过读写共享存储来通信; MQ 就是其中一种方法, 它可以帮助我们解耦客户端与服务端. 不过需要注意的是 MQ 是单向通信. 常用的开源 MQ 有 RabbitMQ,Kafka
同步化
在分布式系统中, 与进程间通信紧密相关的问题是进程间如何协作和同步. 进程协作使得进程可以共享资源. 与同步相关的二个主题是分布式互斥(保护共享资源不会被多个进程同时访问)和分布式事务.
在分布式事务中, 必须要保证一个事务中的操作要么全部发生, 要么一个都不发生.
分布式事务是出了名的难以实现; 在实践中, 最常用的解决方案是二阶段提交协议 2PC (two-phase commit protocol), 由 Gray 在 1978 年提出; Java 中的 JTA, 就是使用的 2PC.
2PC 的主要缺点是不能很好的处理协作者故障, 导致所有参与者都被迫在协作者恢复之前阻塞. Skeen 1981 开发了一种 2PC 的变种, 三阶段提交协议 3PC, 但在实际中用的并不多, 因为在 2PC 中出现阻塞的情况极少发生.
通过 2PC 实现的分布式事务的问题在于, 它横跨多个服务, 由于节点间通信时延等因素, 导致低吞吐量以及低可用性. 微服务鼓励服务间的无事务协作, 追求最终一致性以及通过重试或补偿操作处理问题.
一致性与复制
分布式系统的一个重要问题是数据的复制. 一般进行数据复制的主要目的是为了提高系统的可靠性(部分副本被损坏后, 不会影响整个系统)或提高性能(副本可以分担工作负荷).
实现数据复制的一个主要难题是如何保持各个副本的一致性. 通常, 在大规模分布式系统中有效的实现数据的一致性模型是很困难的. 事实上, 一致性模型有很多, 但通常我们关心的只有强一致性和最终一致性.
在诸多一致性算法中, 一个不得不提的算法, 是 Leslie Lamport 在 1989 年提出的一致性算法, Paxos; 在相当一段时间中, Paxos 基本就是 Consensus Algorithm 的同义词.
对于分布式存储系统来说, 一个相关的理论是 Eric Brewer 的 CAP; CAP 断言: 对于一个分布式数据存储系统来说, 不可能同时保证可容忍网络分区(Partition Tolerance), 可用性 (Availability), 数据一致性 (Consistency).
Fault Tolerance 容错
容错 分布式系统不同于单机系统的一个特性就是它可以容许部分失效. 当分布式系统中的一个组件发生故障就可能会产生部分失效. 分布式系统设计中的一个重要目标就是容错, 意味着系统即使发生故障, 依然可以继续提供服务.
处理故障的关键技术 - 冗余, 为了避免单点故障, 服务大多以集群形式存在
故障检测
要很好的屏蔽故障, 需要先检测出故障。 在分布式系统中,故障检测是容错的基石; 要检测进程故障
故障隔离
…
故障恢复
容错的基本要求是可以从错误中恢复
Transient Fault handling
Retry 重试策略,适用于处理短暂故障(transient fault), 比如网络抖动; 如果预估依赖的服务在未来一段时间内依然有很高的概率会失败,可以考虑 Circuit Break 熔断以及考虑是否可以进行业务降级
Checkpoint 检查点
…